





ズレとブレ
統計学では、「推定が当たったかどうか」だけではなく、
- どれくらいズレているか
- どれくらいブレているか
を考えます。この違いを理解するために、まずは的当てを想像してみましょう。
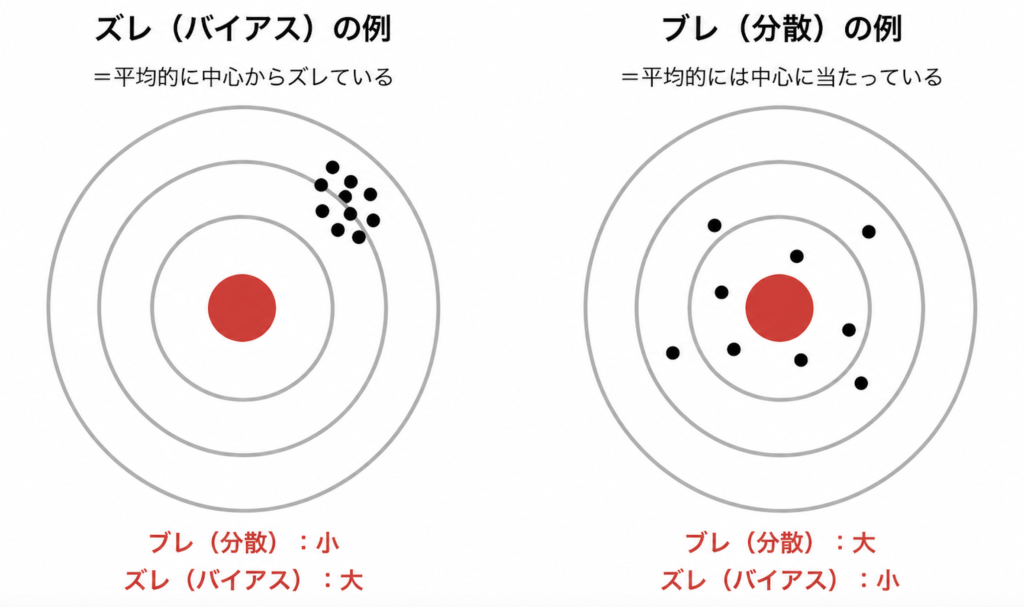
「ズレ」と「ブレ」のうち、“平均的にズレていない性質”を表す概念が、不偏性です。式で書くとこんな感じ
$$E[\hat{\theta}]=\theta$$
不偏性は統計学において非常に重要な考え方ですが、同時に「不偏なら最強」というわけでもありません。この記事では、不偏性の意味と必要性、そして限界について理論的に解説していきます。
推定とはなにか
統計学では、知りたい真の値を「母数」と呼びます。例えば母平均を \(\mu\) とします。しかし通常、母集団全体を観測することはできません。そこで、母集団から一部だけを取り出して調査します。その標本を
$$X_1, X_2, \dots, X_n$$
とすると、母平均を推定する最も基本的な方法は標本平均です。
$$\bar{X} = \displaystyle\frac{1}{n}\sum_{i=1}^n X_i$$
ここで重要なのは、\(\bar{X}\) は固定値ではなく、「確率変数」であるということです。つまり、標本の取り方によって値が変わります。
「あるときは真の平均より大きくなり、あるときは小さくなる。」
そのため統計学では、
「この推定方法は長期的にどのような性質を持つのか」
を考えます。
不偏性の定義
推定量 \(\hat{\theta}\) が、母数 \(\theta\) に対して不偏であるとは、
$$E[\hat{\theta}] = \theta$$
が成立することを言います。これは、
「同じ標本抽出を何回も繰り返したとき、推定値の平均が真の値に一致する」
という意味です。例えば標本平均について期待値を計算すると、
$$E[\bar{X}] = E\left[ \displaystyle\frac{1}{n}\sum_{i=1}^n X_i \right]$$
$$= \displaystyle\frac{1}{n}\sum_{i=1}^n E[X_i]$$
各標本の期待値は母平均なので、\(E[X_i] = \mu\) となり、
$$= \displaystyle\frac{1}{n}(\mu + \mu + \cdots +\mu)$$
$$= \displaystyle\frac{1}{n} \cdot n\mu =\mu$$
したがって、
$$E[\bar{X}] = \mu$$
となります。つまり標本平均は、母平均の不偏推定量です。
なぜ必要なのか
不偏性が重要視される理由は、「推定方法そのものに偏りがない」ことを保証するからです。例えば、次のような推定量を考えます。
$$\hat{\mu} = \bar{X} + 10$$
この期待値は、
$$E[\hat{\mu}] = E[\bar{X}] + 10 = \mu + 10$$
となります。つまり、この推定量は平均的に常に10だけ大きく推定してしまいます。このようなズレを「バイアス(偏り)」と呼びます。バイアスは、
$$\mathrm{Bias}(\hat{\theta}) = E[\hat{\theta}] – \theta$$
で定義されます。不偏性とは、
$$\mathrm{Bias}(\hat{\theta}) = 0$$
という状態です。つまり統計学では、「平均的に間違った推定をしていないか」を非常に重視しているのです。特に頻度主義統計では、同じ実験を無限回繰り返したときの長期的な性質を重要視します。不偏性は、その代表的な概念と言えます。
不偏性だからと言って最強ではない
ここが統計学の本質的に面白い部分です。不偏性は重要ですが、「不偏だから良い推定量」とは限りません。なぜなら、推定量には「ズレ」だけではなく、「ブレ」も存在するからです。
例えば、不偏推定量でも分散が非常に大きければ、推定値は毎回大きく変動します。一方で、少しバイアスがあっても、ブレが小さい推定量の方が実用的には優れている場合があります。
推定誤差全体を評価する代表的な指標が、平均二乗誤差(MSE)です。
$$\mathrm{MSE} = E[(\hat{\theta}-\theta)^2]$$
このMSEは、
\begin{aligned}
\mathrm{MSE}&=E \big[\{ (\hat{\theta}-E[{\hat{\theta}}]) + (E[\hat{\theta}]-\theta) \}^2 \big]\\
&=E \big[(\hat{\theta}-E[{\hat{\theta}}])^2 + 2(\hat{\theta}-E[\hat{\theta}])(E[\hat{\theta}]-\theta)+ (E[\hat{\theta}]-\theta)^2\big]\\
&=E[(\hat{\theta}-E[{\hat{\theta}}])^2] + (E[\hat{\theta}]-\theta)^2\\
&=\mathrm{Var}(\hat{\theta}) + \mathrm{Bias}(\hat{\theta})^2
\end{aligned}
※\(E[\hat{\theta}-E[\hat{\theta}]]=E[\hat{\theta}]-E[\hat{\theta}]=0\)
と分解できます。つまり誤差には、
- 分散(ブレ)
- バイアス(ズレ)
改めて的の例を見てみてください!
の両方が関係しているのです。これは機械学習にもつながる重要な考え方です。例えばリッジ回帰では、あえて少しバイアスを入れる代わりに分散を減らし、未知データへの予測性能を高めています。つまり実務では、
の方が重要になることが多いのです。
まとめ
不偏性とは、
$$E[\hat{\theta}] = \theta$$
が成立する性質であり、「長期的に見て平均的に正しい推定」を意味します。統計学では、推定方法そのものに偏りがないことを重視するため、不偏性は非常に重要な概念です。一方で、現実のデータ分析では標本数は有限であり、実際には1回しか推定できないことも多くあります。そのため、
- 不偏性
- 分散
- MSE
などを総合的に考える必要があります。統計学は、「1回当たるか」ではなく、「長期的にどう振る舞うか」を考える学問です。不偏性は、その統計学的な思想を最もよく表している概念の1つと言えるでしょう。
さいごまで読んでいただきありがとうございました!
- 大学受験数学で困っている学生の方
- 公務員試験の数学で困っている学生/社会人の方
- 統計学(統計検定)の勉強で困っている学生/社会人の方
個人家庭教師やってるので、ぜひコメントやXでご連絡ください。(Xはこちら)
時間や料金などは相談して決められればと思っておりますが、塾に通うよりは高コスパかなと思います。また、基本的にはオンラインでの授業を想定していますが、場所によっては直接の指導が可能です。(プロフィール)
これまでは塾講師や高校で働いていたのですが、現在はデータサイエンティストとして活動しています。社会やビジネスで数学がどのように使われているのか、そういった話も交えながら進められればと思っております。
数学に困っている方の一助になれれば幸いです。
ご連絡お待ちしております。
質問や感想はコメントへ!